
Running Ruby on Rails with AWS Lambda (CloudDive)

CloudDive is a monthly podcast presented by the 100DaysOfCloud community where we dive deep into specific cloud topics or projects with an expert guest.
This accompanying article expands on the original podcast topic to help provide more technical information if you are looking to implement Ruby on Rails with AWS Lambda using Lamby.
What is Lamby?
Lamby is a ruby gem that enables you to run your Ruby on Rails application on AWS Lambda with little-to-modification to your existing project.
A Return To the Golden Age
Imagine the productivity and happiness of Ruby on Rails but with nearly-zero DevOps responsibility. You might be thinking, well such a service exists and it's called Heroku or AWS Elastic Beanstalk.
But there are clear differences between your PaaS and your Serverless compute service:
- simpler tools for deployment
- billing that occurs at 100ms instead of hourly
- no hassle configurations like setting up callbacks in appspec.yml
- synergies with existing serverless tooling
And if you have reservations I appreciate the skepticism. The purpose of this CloudDive is to answer all the possible questions and we are fortunate to be accompanied on this dive by Ken Collins.
Ken Collins
Ken has a love for both Ruby and Serverless, currently is the Principal Engineer at CustomInk. Ken is the creator of the Lamby, the open-source gem that allows you to run Ruby on Rails in AWS Lambda. This one of his many open-source contributions to ruby and serverless so it makes that AWS has recognized him as an AWS Serverless Hero
If you want to connect with Ken you can find him on various social media platforms:
- https://dev.to/metaskills
- https://www.linkedin.com/in/metaskills/
- https://twitter.com/metaskills
Understanding How Lamby Works
AWS Lambda Recap
Let us do a quick recap on how AWS Lambda works. AWS Lambda is a Function as a Service (FaaS). Meaning that you choose your runtime, upload your code and the service takes care of everything else.
The entry point to a Lambda function is its handler. We can name our handler whatever we want and in this case, its called app.handler
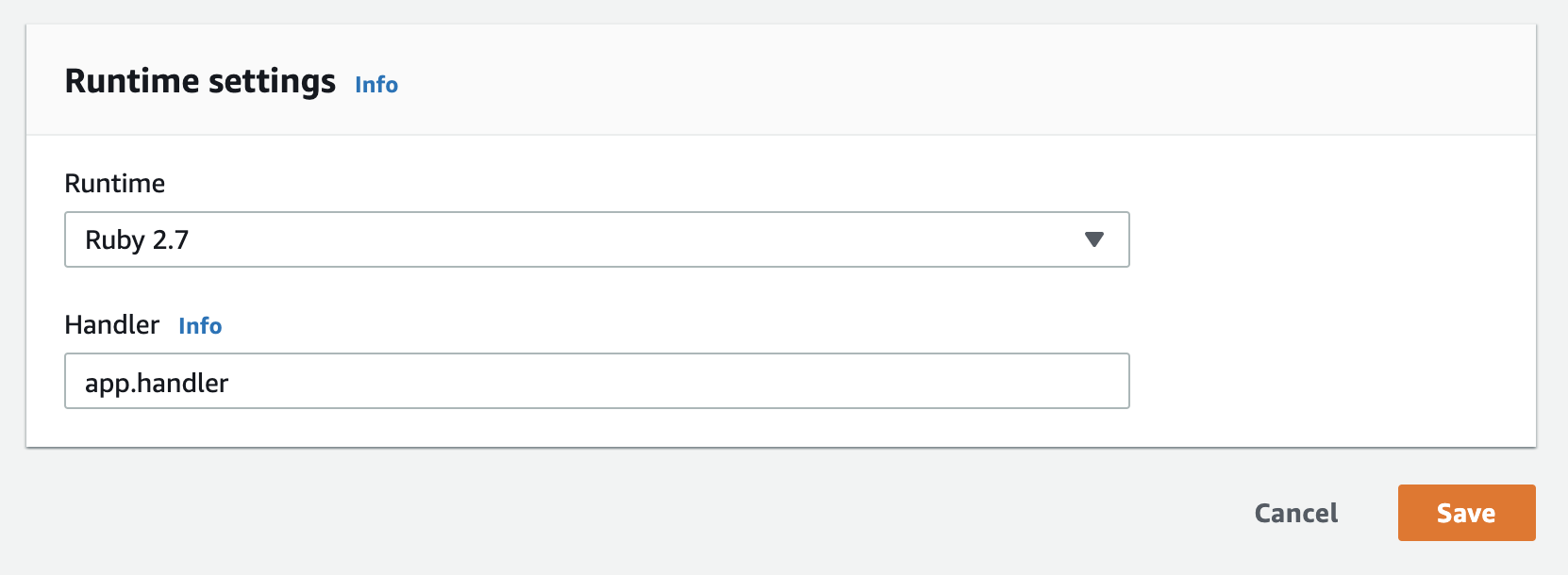
That means Lambda expects us to have a ruby file called app.rb and it will call the function named handler. AWS Lambda has an inline editor where you can edit your handler function.
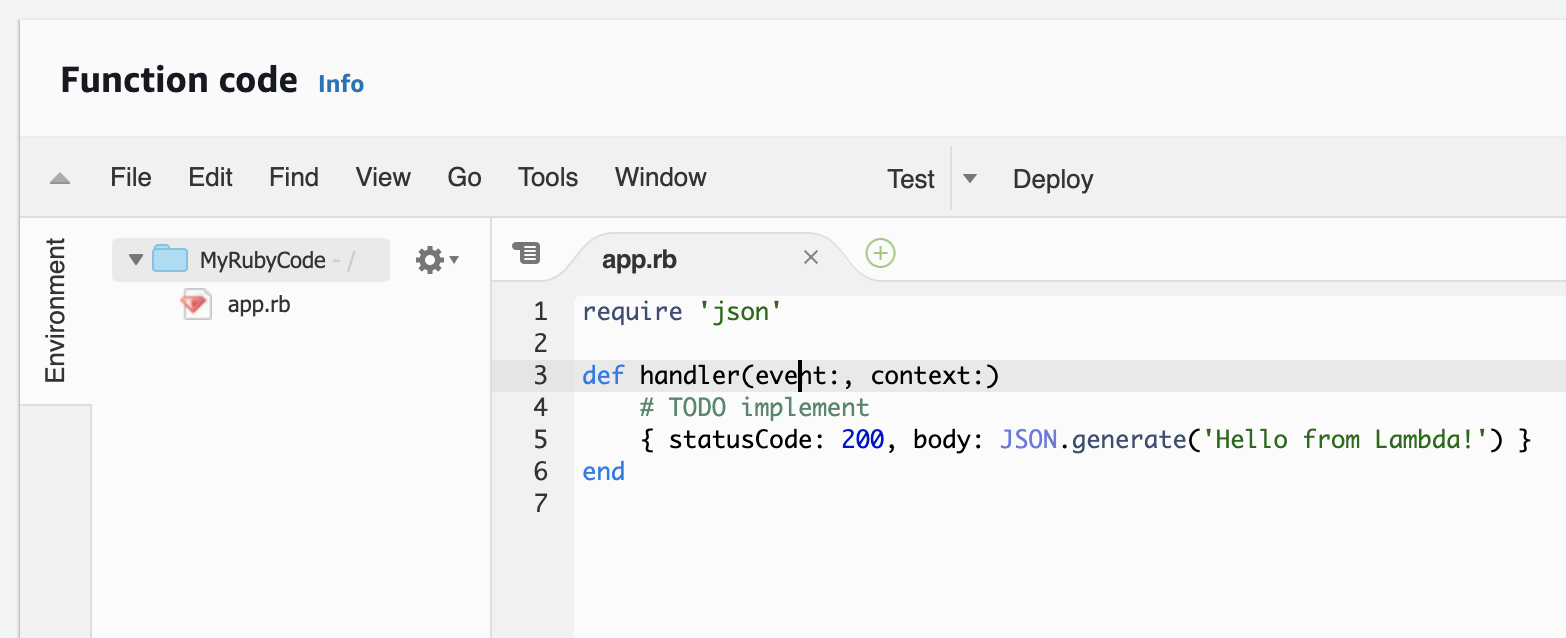
So you might mistakenly think Lambda is intended to contain only a single function but the reality is that Lambda just runs a single function. You can have as many functions and file as you like. In the end, it just going to call that handler.
So how much code can we place into a Lambda? According to the Lambda Limits once our code exceeds 3 MB we can no longer use the inline editor and have to upload a zip deployment package.
We are allowed 50MB compressed and when it uncompressed onto Lambda we're allowed 250MB including Lambda layers. So we have lots of room to work with here so we don't have to keep thinking small with Lambda.
Lamby Package
So to prepare your Rails application for Lamby you're going to add the Lamby gem to your Gemfile and within your Rails Root directory you'll create your Lambda handler which in this case is named app.rb
And here is the contents of that app.rb
ENV['RAILS_SERVE_STATIC_FILES'] = '1'
require_relative 'config/boot'
require 'dotenv' ; Dotenv.load ".env.#{ENV['RAILS_ENV']}"
require 'lamby'
require_relative 'config/application'
require_relative 'config/environment'
$app = Rack::Builder.new { run Rails.application }.to_app
def handler(event:, context:)
Lamby.handler $app, event, context, rack: :http
end
So there are two important lines. The first is that when Rails boots up via our config/boot it will initialize our application via Rails.application, then we are using Rack::Builder.new to construct a Rack application.
$app = Rack::Builder.new { run Rails.application }.to_app
Then we are passing our Rack application to Lamby, and the Lamby gem sprinkles in a bit of magic.
Lamby.handler $app, event, context, rack: :http
One of the nice things about Lamby is that the gem is incredibly small. You can open up the gem's lib directory and quickly make sense of said magic that it is sprinkled within.
If you've ever maintained a Rails app for a decade, there is a fear of a convenient but very complex gem that you become reliant on but then eventually becomes unmaintained. So it's a relief to see that it's very simple and easy to understand.
The story with Rack
So why so do we need to wrap our Rails app with a Rack app? Well, the truth is that you probably always have been. If you have ever used a web-server such as Unicorn, Puma or Phusion Passenger, they will wrap your Ruby on Rails app as a Rack app.
Rack is a web server interface, meaning that it acts as an adapter by standardizing how it handles HTTP requests and responses.
Rails and many other ruby web-frameworks are rack-compatible. So for the most part Lamby runs Rack apps. I say for the most part because some of the magic is optimized for Rails, but you can run other web-frameworks in Lamby such as Sinatra though you'll have to check with Ken.
Getting Started the Easy Way
So there is a bit more than just adding a single app.rb file to your Rails app, zipping and uploading to Lambda. You will need to package all of your gems into your Rails vendor directory.
Ken has provided us with a good example application that has all the scripts we'll need to:
- package the gems
- create a SAM application with needed infrastructure eg. API Gateway, Lambda
- create a local development environment via docker
- deploy our application
So if you can get the SAM CLI installed you can scaffold this example project:
sam init --location "gh:customink/lamby-cookiecutter"
And once you have a copy of this example project this you can just copy over the necessary files to your application:
- app.rb
- Makefile
- bin/*
I know there are a lot of lingering questions so let's get into them:
Okay, But what about...
So these are all the questions I had for Ken that had me still on the fence about running Ruby on Rails with Lambda.
But isn't it a bad idea to load an entire web-application framework into a Lambda?
Many programmers think of SOLID or Single Principle Design (SPD) and interpret AWS Lambda to be a single function in nature. If you were to ask the room, they would be split between single or multi-use lambdas.
Lambda is just a form of computing and we have in the past already been running a collection of functions that act as a service or domain in containers or a larger collection of functions that act as a monolith on a VM.
It has become very popular in recent years to run a single containerized version of Ruby on Rails, so why not think of Lambda as a managed pre-defined serverless container?
But isn't there already a serverless way to run Rails using the Ruby on Jets framework?
Ruby on Jets existed before AWS supported an official ruby runtime and its approach to serverless Rails reflects that. Ruby on Jets does use Rails as its underlying libraries but there is a lot of boilerplate on top making it an entirely different framework.
Instead of deploying an entire Rails app to a Lambda it will take each of your Rails controller actions and deploy them to individual Lambdas all backed by an API Gateway endpoint. It will map your Rails routes as the schema for your API Gateway. There is much more to the Ruby on Jets framework.
So you are buying into a very opinionated framework that entangles and distributes your Rails application with multiple serverless servers. This could be good or bad depending on you feel about the architecture and what kind of flexibility you'll need in your serverless architecture going forward.
With Lamby you have a lot more freedom in your architecture because you simply are deploying a Rails app onto a Lambda.
But how does routing work?
You have a single Lambda, but you have multiple Rails routes, so you're thinking how are all these different endpoints going to map to a single Lambda function.
So your Lambda is either going to be backed by API Gateway REST, API Gateway HTTP or an Application Load Balancer.
Lamby.handler $app, event, context, rack: :http
Lamby.handler $app, event, context, rack: :rest
Lamby.handler $app, event, context, rack: :alb
fun fact, when using
:httpit supports both v1 and v2 payloads via auto-detection.
So let us say we have a web-application that defines the following Rails routes:
GET /tasks
GET /tasks/:id
GET /tasks/new
GET /tasks/:id/edit
POST /tasks
PUT /tasks/:id
DELETE /tasks/:id
GET /projects
GET /projects/:id
GET /projects/new
GET /projects/:id/edit
POST /projects
PUT /projects/:id
DELETE /projects/:id
Using API Gateway REST you would think you need to create a route for each of the following routes that route to Lambda. Luckily API Gateway REST supports a $default route which will act as a catch-all.
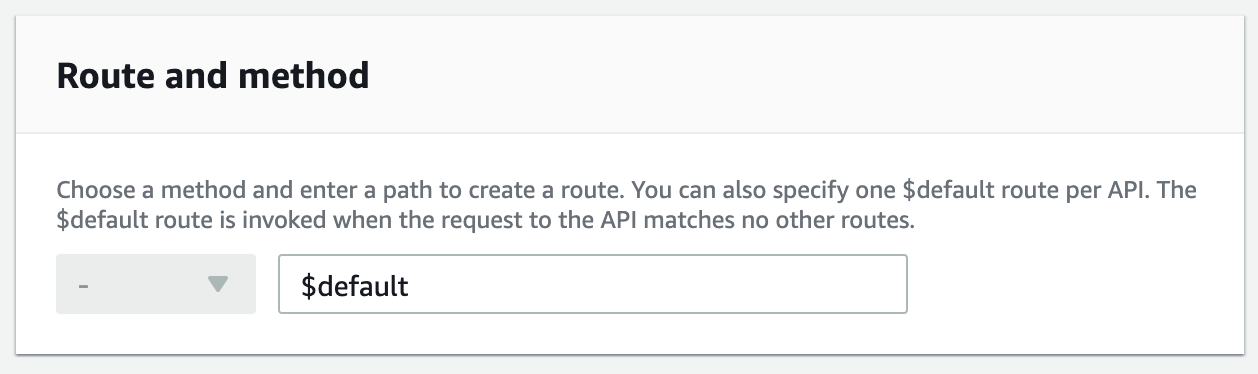
When the HTTP request is forwarded to your Lambda it will have the full path of the request and so Rails will treat the HTTP request as it normally would, using the you Rails route to send it to the corresponding controller action.
API Gateway has catch-all variable paths so it can support this behaviour as well.
Application Load Balancer will by default route all your routes to your Lambda, and with request routing, you can specify subpaths with wildcards so if you just wanted to lift a specific part of your app to a Rails Lamba you could.
If you wanted to break your large Rails app into smaller isolate Rails apps based on the domain and have them all sitting on the same domain with different subpaths you can do this and it's strongly encouraged
/accounts/* => Service that handles self-managed user account
/billing/* => Service handles purchases, subscription and billing details
But how do I connect to a database?
In your Rails app, it would be business as usual with your Postgres or MySQL gem for the database driver. These gems rely on native-extensions so you'll likely want a pre-compiled gem that contains the underlying c binary file.
So for MySQL there Ken has given us mysql2-lambda
For Postgres uncertain right now, but I'll update this article when I found out since it's my primary database.
There are a couple of challenges when connecting AWS Lambda to relational databases.
You need a way of pooling database connections because Lambda can overwhelm the database connection limits of your RDS instance. So this would require you to set up a pooling server so in the case of Postgres this would be using pg_bouncer. AWS now has a managed pooling service you can turn on in AWS Lambda called RDS Proxy with AWS Lambda.
In order for AWS Lamdba to connect to your RDS instance, it will need to reside in the same VPC. You can change AWS Lambda from the AWS managed VPC to your own.
If you want to use Aurora Serverless and Data API Ken has also written an adapter gem for that as well. I think in this case because Data API transverses the internet you don't need to place your Lambda in the same VPC.
If you don't want Data API to leave the AWS network you can create a VPC endpoint to keep all traffic secure and safe inside of AWS.
But how do I handle background jobs?
The most commonly used background job service used by Rails developers is Sidekiq. Sidekiq needs to run its own daemon in a traditional monolith running on a single server so you aren't going to be doing that on AWS Lambda.
Running Sidekiq on another Lambda is possible, at least the web-console, proven by this open-source project.
Sidekiq is reliant on Redis and you aren't going to run that in a Lambda since the database is in-memory, and you can use ElastiCache to host your Redis server. ElastiCache has the limitation in that resources only within the same VPC can connect to your ElastiCache cluster.
Lambda functions can connect to ElastiCache but I don't fully the defaults to that so you'll have to have a fun time following links on StackOverflow
So likely running Sidekiq on Lambda is not feasible or advisable. If you want that Sidekiq it's going to likely need to run a VM on EC2.
This would be a great opportunity to adopt SQS, which is AWS messaging queue. It's not as fast as Sidekiq but it's serverless and just scales. Ken has tutorialized How to use Shoryuken with ActiveJob
Shoryuken is a gem that allows you to write jobs as you normally would in Rails that connect to SQS. You may find the experience much easier than you think.
But what about ruby's that require native-extensions? (c compiled libraries)
Ruby gems that have native-extensions are gems that rely on binary c files. In order to use these gems you need to compile the underlying c programs on the target operating system.
I think Ken has taken care of this for us within his cookie-cutter project because it will set up a docker container with the same Container used by AWS Lambda's ruby runtime.
And he has a script that will package all of the gems in the vendor directory and so I expect that it's going to compile native extensions.
But aren't Rails apps large and doesn't Lambda has a size limit?
My ExamPro platform that's a very robust Ruby on Rails application currently shows 844 MB but after some digging most of this is because of log files, tmp files or assets.
After removing all these files from Rails application is around ~28 MB. When comparing to ExpressJS application where you would think you have a much smaller footprint what I have found is that node_modules alone can balloon out to 20 MB so they are quite comparable in size.
That being said you're going to likey not serve us your larger assets such as an image from your assets/images directory, so this will force you into best practice of placing those on S3 and CloudFront.
Again, Ken has solved this for us as well as he has tutoralized How to host and precompile your assets
So you can still use Webpacker or Sprockets as you normally would.
But doesn't Rails have a very slow boot time?
It depends on how large is your existing web-application. I think if you adopted Lamby on day 1, you'd be more adopted to breaking up your web-application into multiple Lamby's based on service domain and so a very slow boot time would not be problematic.
If the boot time does pose an issue, you can start your migration by breaking up domains within your Rails web-application into Rails Engines.
Rail Engine is a plugin system where you can self-contain Rails into a Gem and you can mount that gem into your existing Rails application allowing you to isolate the business-specific code to that engine.
When you have achieved isolation running in your existing Rails monolith you can simply promote this Rails Engine into a full-size Rails app by creating a parent dummy app and that can be deployed to Lamby
If you have to rollback because you need to tweak Lambda's performance or it wasn't the right fit it's easy to do so.
Generally, boot time should be a non-issue. And if it were, AWS has provisioned currency
But what happens to Puma?
You don't need a ruby web-server. Puma is just gone. You don't have to worry about managing a cluster of instances. Each Lambda is a single process of Rails. You're not thinking about multi-threading. It's dead simple.
That to me was the wow moment with Lamby. I never want to deal with debugging a Puma daemon ever again.
But what about cold-starts?
Not as problematic as you might expect. You'll encounter cold-starts less frequently because you have a Lambda that is handling multiple routes keeping your lambda quite warm.
I was astonished at how fast the sample Lamby app was without Provisioned Concurrency.
I think I plan to use Provisioned Concurrency so I'll have to report back on cost and if I really need to use it or not.
But how am I supposed to use an Application Performance Monitoring (APM) for a Rails app running in a Lambda?
I think NewRelic's APM can run on Lambda.
I am not certain about DataDog or RayGun, Skylight or other APM providers.
I would think the hurdle is how is the APM agent going to report back to their respected service.
Ken is used to using New Relic but is considering just utilizing CloudWatch and again Ken has tutorialized how we can gain observability using CloudWatch Dashboards, CloudWatch Embedded Metric, CloudWatch Log Insights
For some not being able to use the DataDog APM could prove a deal-breaker because when you're in an eco-system like DataDog where you want to correlate APM traces to SLOs you then have to figure how how to construct all of that yourself on AWS.
CloudWatch Log Insights is truly revolutionary so I think if you're growing up with Lamby and Log Insights you'll find it cost-effective and convenient.
But what happens when Lambda decides to release to deprecate an old Ruby version and I have to upgrade to a new one?
Then you have to upgrade your Rails app and ideally, that is what you're supposed to be doing all along with your Monolith running on VM anyway. AWS actually sells this as a security feature where they are forcing you into best practices.
This could be worrisome if your Rails app relies on gems that convenient and deeply rooted in your system but then one day the maintainers stop supporting their gem and keeping it current.
This is a current problem for me on one of my existing Rails app where I can't upgrade because of Paperclip and I'm stuck on Rails 4. So it requires major uplift, but honestly, that is on me for relying on many gems that provide a nice DSL instead of just choosing a less DRY but simpler solution.
But how I am suppose to Rails Console to live-debug my server?
You can't as far as I'm aware of. It is possible with Rails Console on ECS
It's not good practice to be live debugging your server anyway.
Some parting resources
Just a few links for you to explore on your own:
- https://technology.customink.com/blog/2020/03/13/using-aws-sam-cookiecutter-project-templates-to-kickstart-your-ambda-projects/
- https://dev.to/aws-heroes/aws-lambda-microservice-workshop-using-s3-libvips-ruby-4o96
- https://github.com/customink/aws-embedded-metrics-customink


